Deep Learning
Natural Language Processing
Awesome Guides
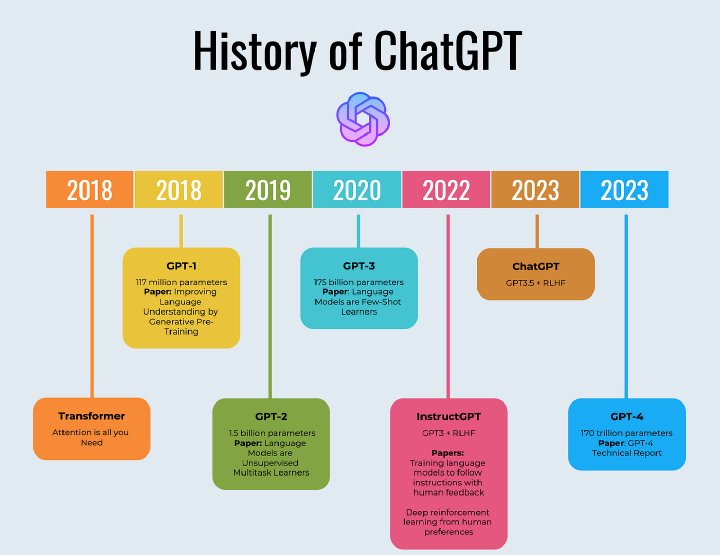
Chat Gpt Series
Everything Programmers need to learn about GPT — Using OpenAI and Understanding Prompting
ChatGPT’s free conversational interface offers a tantalizing glimpse into the future of AI.
read more