
With the advent of so many computing and serving frameworks, it is getting stressful day by day for the developers to put a model into production .
read more
Big Data has become synonymous with Data engineering. But the line between Data Engineering and Data scientists is blurring day by day.
read more
Every few years, some academic and professional field gets a lot of cachet in the popular imagination.
read more
Recently, I was reading Rolf Dobell’s The Art of Thinking Clearly, which made me think about cognitive biases in a way I never had before.
read more
I have found myself creating a Deep Learning Machine time and time again whenever I start a new project.
read more
Python provides us with many styles of coding. And with time, Python has regularly come up with new coding standards and tools that adhere even more to the coding standards in the Zen of Python.
read more
Have you ever thought about how toxic comments get flagged automatically on platforms like Quora or Reddit?
read more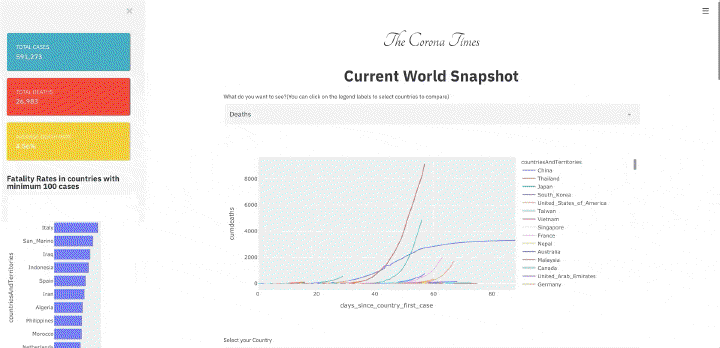
It seems that the way that I consume information has changed a lot.
read more
With Coronavirus on the prowl, there has been a huge demand across the world for MOOCs as schools and universities continue to shut down.
read more
Feeling Helpless? I know I am. With the whole shutdown situation, what I thought was once a paradise for my introvert self doesn’t look so good when it is actually happening.
read moreAbout Me

I’m a Machine Learning Engineer based in London, where I am currently working with Roku .
Know More