The Ultimate Guide to using the Python regex module

One of the main tasks while working with text data is to create a lot of text-based features.
One could like to find out certain patterns in the text, emails if present in a text as well as phone numbers in a large text.
While it may sound fairly trivial to achieve such functionalities it is much simpler if we use the power of Python’s regex module.
For example, let’s say you are tasked with finding the number of punctuations in a particular piece of text. Using text from Dickens here.
How do you normally go about it?
A simple enough way is to do something like:
target = [';','.',',','–']
string = "It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way – in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only.**"
num_puncts = 0
for punct in target:
if punct in string:
num_puncts+=string.count(punct)
print(num_puncts)
19
And that is all but fine if we didn’t have the re module at our disposal. With re it is simply 2 lines of code:
import re
pattern = r"[;.,–]"
print(len(re.findall(pattern,string)))
19
This post is about one of the most commonly used regex patterns and some regex functions I end up using regularly.
What is regex?
In simpler terms, a regular expression(regex) is used to find patterns in a given string.
The pattern we want to find could be anything.
We can create patterns that resemble an email or a mobile number. We can create patterns that find out words that start with a and ends with z from a string.
In the above example:
import re
pattern = r'[,;.,–]'
print(len(re.findall(pattern,string)))
The pattern we wanted to find out was r’[,;.,–]’. This pattern captures any of the 4 characters we wanted to capture. I find regex101 a great tool for testing patterns. This is how the pattern looks when applied to the target string.
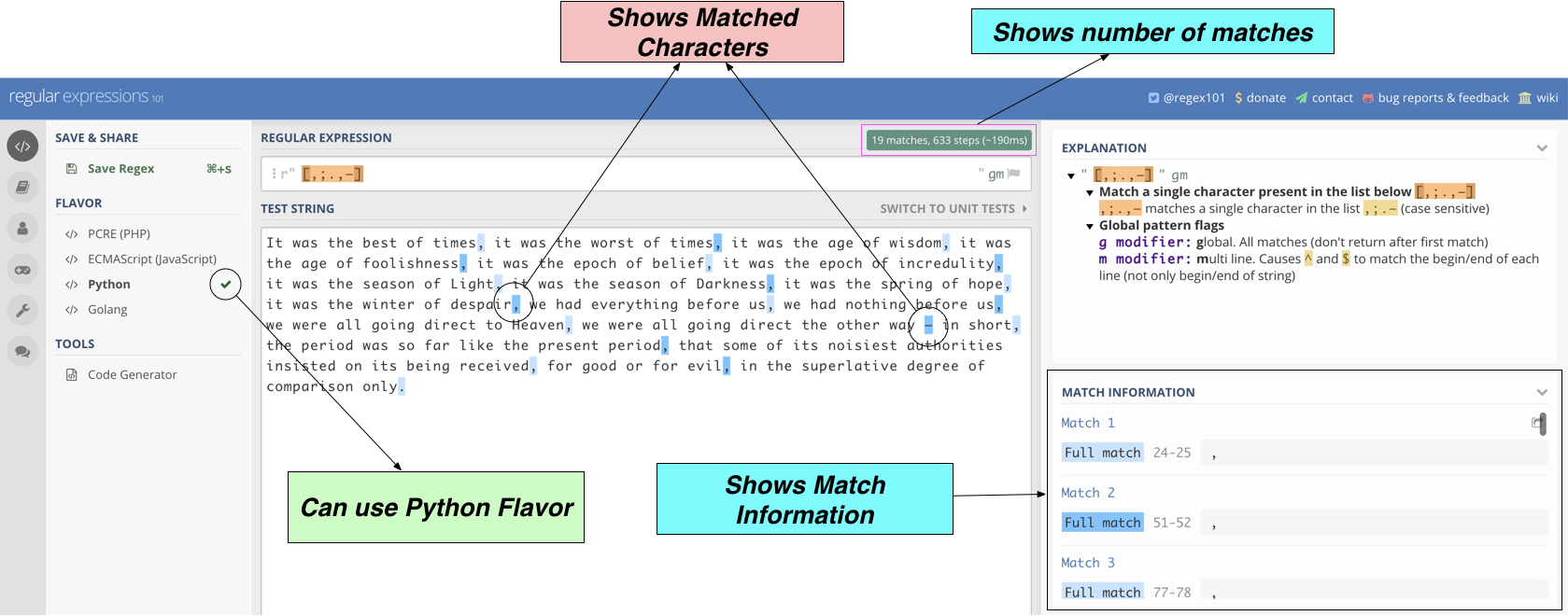
As we can see we are able to find all the occurrences of ,;.,– in the target string as required.
I use the above tool whenever I need to test a regex. Much faster than running a python program again and again and much easier to debug.
So now we know that we can find patterns in a target string but how do we really create these patterns?
Creating Patterns

The first thing we need to learn while using regex is how to create patterns.
I will go through some most commonly used patterns one by one.
As you would think, the simplest pattern is a simple string.
pattern = r'times'
string = "It was the best of times, it was the worst of times."
print(len(re.findall(pattern,string)))
But that is not very useful. To help with creating complex patterns regex provides us with special characters/operators. Let us go through some of these operators one by one. Please wait for the gifs to load.
1. the [] operator
This is the one we used in our first example. We want to find one instance of any character within these square brackets.
[abc]- will find all occurrences of a or b or c.
[a-z]- will find all occurrences of a to z.
[a-z0–9A-Z]- will find all occurrences of a to z, A to Z and 0 to 9.

We can easily use this pattern as below in Python:
pattern = r'[a-zA-Z]'
string = "It was the best of times, it was the worst of times."
print(len(re.findall(pattern,string)))
There are other functionalities in regex apart from .findall but we will get to them a little bit later.
2. The dot Operator
The dot operator(.) is used to match a single instance of any character except the newline character.
The best part about the operators is that we can use them in conjunction with one another.
For example, We want to find out the substrings in the string that start with small d or Capital D and end with e with a length of 6.
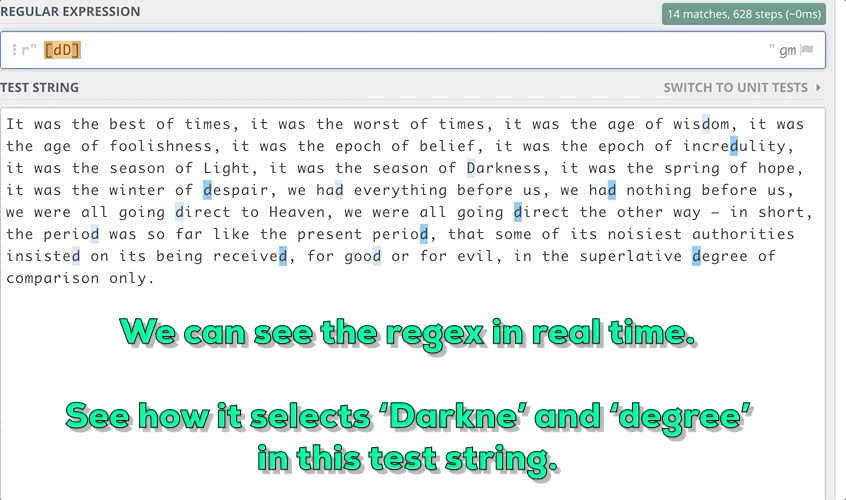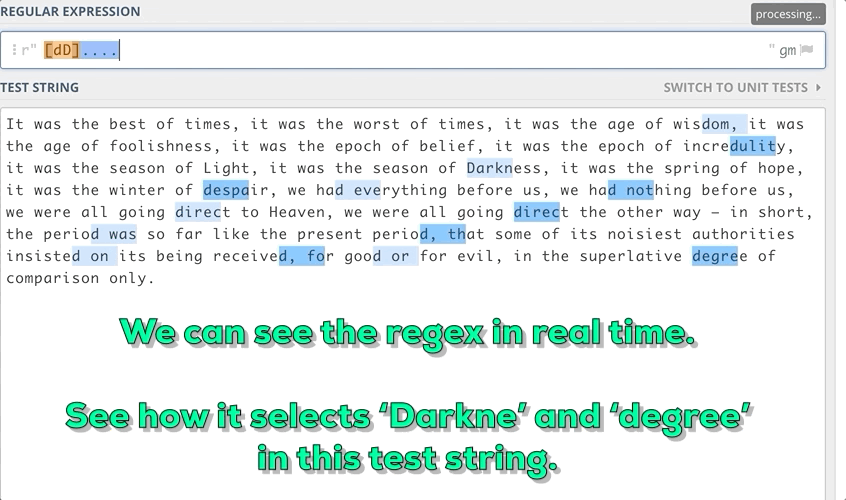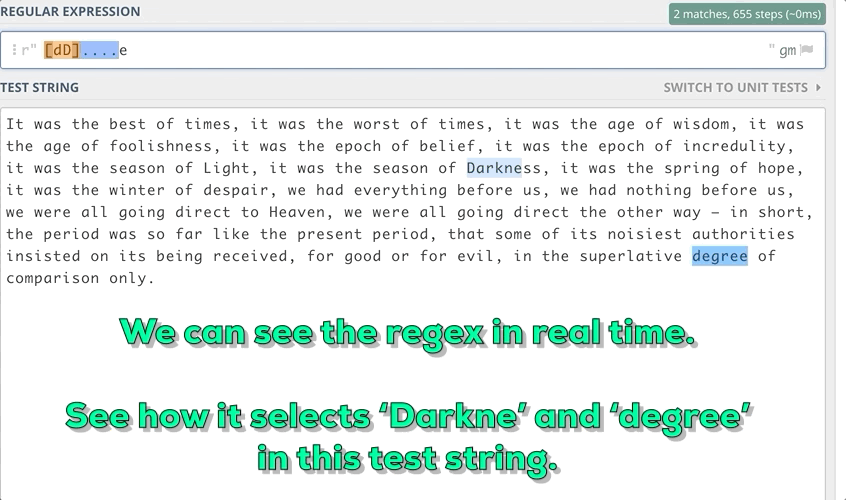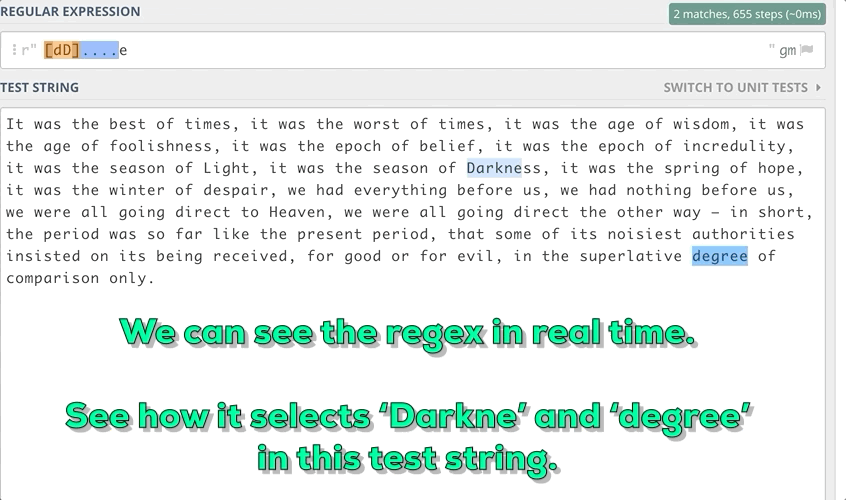
3. Some Meta Sequences
There are some patterns that we end up using again and again while using regex. And so regex has created a few shortcuts for them. The most useful shortcuts are:
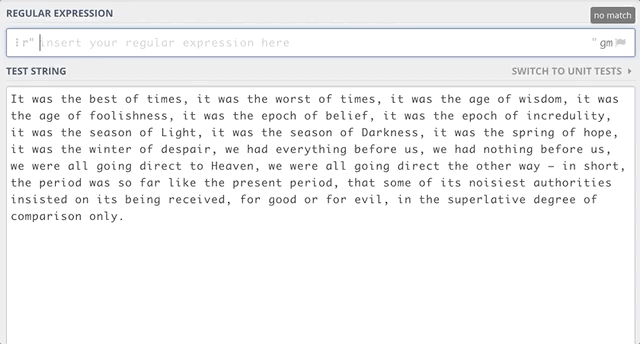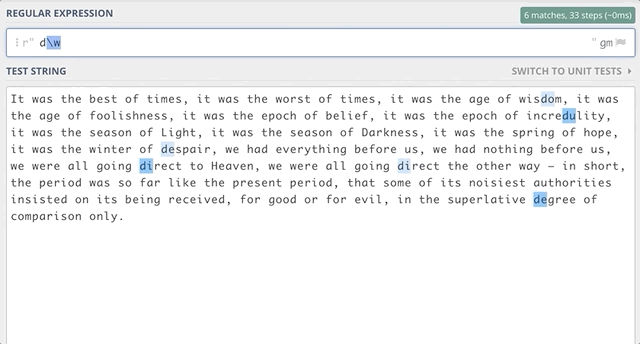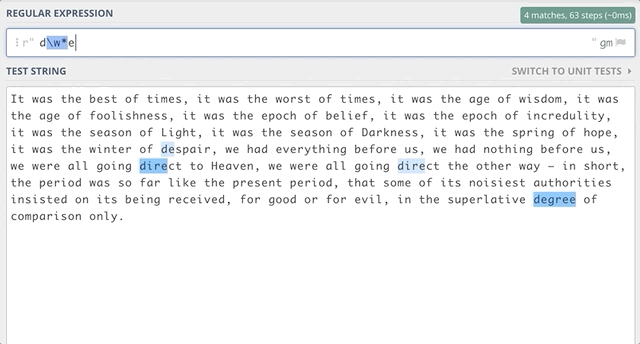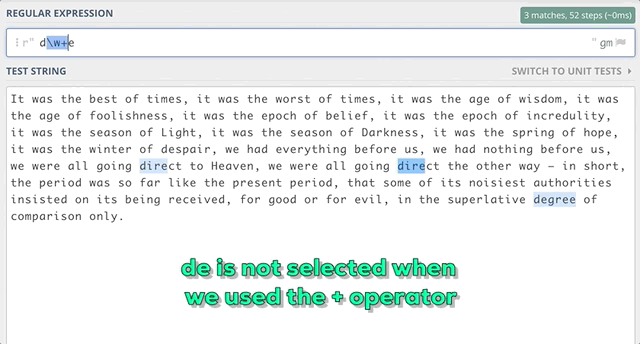
\w, Matches any letter, digit or underscore. Equivalent to [a-zA-Z0–9_]
\W, Matches anything other than a letter, digit or underscore.
\d, Matches any decimal digit. Equivalent to [0–9].
\D, Matches anything other than a decimal digit.
4. The Plus and Star operator

The dot character is used to get a single instance of any character. What if we want to find more.
The Plus character +, is used to signify 1 or more instance of the leftmost character.
The Star character *, is used to signify 0 or more instance of the leftmost character.
For example, if we want to find out all substrings that start with d and end with e, we can have zero characters or more characters between d and e. We can use: d\w*e
If we want to find out all substrings that start with d and end with e with at least one character between d and e, we can use: d\w+e
We could also have used a more generic approach using
\w{n} - Repeat \w exactly n number of times.
\w{n,} - Repeat \w at least n times or more.
\w{n1, n2} - Repeat \w at least n1 times but no more than n2 times.
5. ^ Caret Operator and $ Dollar operator.
^ Matches the start of a string, and $ Matches the end of the string.

6. Word Boundary
This is an important concept.
Did you notice how I always matched substring and never a word in the above examples?
So, what if we want to find all words that start with d?
Can we use d\w* as the pattern? Let’s see using the web tool.

Regex Functions
Till now we have only used the findall function from the re package, but it also supports a lot more functions. Let us look into the functions one by one.
1. findall
We already have used findall. It is one of the regex functions I end up using most often. Let us understand it a little more formally.
Input: Pattern and test string
Output: List of strings.
#USAGE:
pattern = r'[iI]t'
string = "It was the best of times, it was the worst of times."
matches = re.findall(pattern,string)
for match in matches:
print(match)
It
it
2. Search

Input: Pattern and test string
Output: Location object for the first match.
#USAGE:
pattern = r'[iI]t'
string = "It was the best of times, it was the worst of times."
location = re.search(pattern,string)
print(location)
<_sre.SRE_Match object; span=(0, 2), match='It'>
We can get this location object’s data using
print(location.group())
'It'
3. Substitute
This is another great functionality. When you work with NLP you sometimes need to substitute integers with X’s. Or you might need to redact some document. Just the basic find and replace in any of the text editors.
Input: search pattern, replacement pattern, and the target string
Output: Substituted string
string = "It was the best of times, it was the worst of times."
string = re.sub(r'times', r'life', string)
print(string)
It was the best of life, it was the worst of life.
Some Case Studies:
Regex is used in many cases when validation is required. You might have seen prompts on websites like “This is not a valid email address”. While such a prompt could be written using multiple if and else conditions, regex is probably the best for such use cases.
1. PAN Numbers

In India, we have got PAN Numbers for Tax identification rather than SSN numbers in the US. The basic validation criteria for PAN is that it must have all its letters in uppercase and characters in the following order:
<char><char><char><char><char><digit><digit><digit><digit><char>
So the question is:
Is ‘ABcDE1234L’ a valid PAN?
How would you normally attempt to solve this without regex? You will most probably write a for loop and keep an index going through the string. With regex it is as simple as below:
match=re.search(r'[A-Z]{5}[0–9]{4}[A-Z]','ABcDE1234L')
if match:
print(True)
else:
print(False)
False
2. Find Domain Names

Sometimes we have got a large text document and we have got to find out instances of telephone numbers or email IDs or domain names from the big text document.
For example, Suppose you have this text:
<div class="reflist" style="list-style-type: decimal;">
<ol class="references">
<li id="cite_note-1"><span class="mw-cite-backlink"><b>^ ["Train (noun)"](http://www.askoxford.com/concise_oed/train?view=uk). <i>(definition – Compact OED)</i>. Oxford University Press<span class="reference-accessdate">. Retrieved 2008-03-18</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Train+%28noun%29&rft.genre=article&rft_id=http%3A%2F%2Fwww.askoxford.com%2Fconcise_oed%2Ftrain%3Fview%3Duk&rft.jtitle=%28definition+%E2%80%93+Compact+OED%29&rft.pub=Oxford+University+Press&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li>
<li id="cite_note-2"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Atchison, Topeka and Santa Fe Railway (1948). <i>Rules: Operating Department</i>. p. 7.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.aulast=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.btitle=Rules%3A+Operating+Department&rft.date=1948&rft.genre=book&rft.pages=7&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li>
<li id="cite_note-3"><span class="mw-cite-backlink"><b>^ [Hydrogen trains](http://www.hydrogencarsnow.com/blog2/index.php/hydrogen-vehicles/i-hear-the-hydrogen-train-a-comin-its-rolling-round-the-bend/)</span></li>
<li id="cite_note-4"><span class="mw-cite-backlink"><b>^ [Vehicle Projects Inc. Fuel cell locomotive](http://www.bnsf.com/media/news/articles/2008/01/2008-01-09a.html)</span></li>
<li id="cite_note-5"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Central Japan Railway (2006). <i>Central Japan Railway Data Book 2006</i>. p. 16.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Central+Japan+Railway&rft.aulast=Central+Japan+Railway&rft.btitle=Central+Japan+Railway+Data+Book+2006&rft.date=2006&rft.genre=book&rft.pages=16&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li>
<li id="cite_note-6"><span class="mw-cite-backlink"><b>^ ["Overview Of the existing Mumbai Suburban Railway"](http://web.archive.org/web/20080620033027/http://www.mrvc.indianrail.gov.in/overview.htm). _Official webpage of Mumbai Railway Vikas Corporation_. Archived from [the original](http://www.mrvc.indianrail.gov.in/overview.htm) on 2008-06-20<span class="reference-accessdate">. Retrieved 2008-12-11</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Overview+Of+the+existing+Mumbai+Suburban+Railway&rft.genre=article&rft_id=http%3A%2F%2Fwww.mrvc.indianrail.gov.in%2Foverview.htm&rft.jtitle=Official+webpage+of+Mumbai+Railway+Vikas+Corporation&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li>
</ol>
</div>
And you need to find out all the primary domains from this text- askoxford.com;bnsf.com;hydrogencarsnow.com;mrvc.indianrail.gov.in;web.archive.org
How would you do this?
match=re.findall(r'http(s:|:)\/\/([www.|ww2.|)([0-9a-z.A-Z-]*\.\w{2,3})',string)](http://www.|ww2.|)([0-9a-z.A-Z-]*\.\w{2,3})',string))
for elem in match:
print(elem)
(':', 'www.', 'askoxford.com')
(':', 'www.', 'hydrogencarsnow.com')
(':', 'www.', 'bnsf.com')
(':', '', 'web.archive.org')
(':', 'www.', 'mrvc.indianrail.gov.in')
(':', 'www.', 'mrvc.indianrail.gov.in')
| is the or operator here and match returns tuples where the pattern part inside () is kept.
3. Find Email Addresses:
Below is a regex to find email addresses in a long text.
match=re.findall(r'([\w0-9-._]+@[\w0-9-.]+[\w0-9]{2,3})',string)
These are advanced examples but if you try to understand these examples for yourself you should be fine with the info provided.
Conclusion

While it might look a little daunting at first, regex provides a great degree of flexibility when it comes to data manipulation, creating features and finding patterns.
I use it quite regularly when I work with text data and it can also be included while working on data validation tasks.
I am also a fan of the regex101 tool and use it frequently to check my regexes. I wonder if I would be using regexes as much if not for this awesome tool.
If you want to know more about NLP, I would like to recommend this awesome Natural Language Processing Specialization . You can start for free with the 7-day Free Trial. This course covers a wide range of tasks in Natural Language Processing from basic to advanced: sentiment analysis, summarization, dialogue state tracking, to name a few.
Thanks for the read. I am going to be writing more beginner-friendly posts in the future too. Follow me up at <strong>Medium</strong> or Subscribe to my <strong>blog</strong> .
About Me

I’m a Machine Learning Engineer based in London, where I am currently working with Roku .
Know More