Take your Machine Learning Models to Production with these 5 simple steps

Creating a great machine learning system is an art.
There are a lot of things to consider while building a great machine learning system. But often it happens that we as data scientists only worry about certain parts of the project.
But do we ever think about how we will deploy our models once we have them?
I have seen a lot of ML projects, and a lot of them are doomed to fail as they don’t have a set plan for production from the onset.
This post is about the process requirements for a successful ML project — One that goes to production.
1. Establish a Baseline at the onset
You don’t really have to have a model to get the baseline results.
Let us say we will be using RMSE as an evaluation metric for our time series models. We evaluated the model on the test set, and the RMSE came out to be 3.64.
Is 3.64 a good RMSE? How do we know? We need a baseline RMSE.
This could come from a currently employed model for the same task. Or by using some very simple heuristic. For a Time series model, a baseline to defeat is last day prediction. i.e., predict the number on the previous day.
Or how about Image classification task. Take 1000 labelled samples and get them classified by humans. And Human accuracy can be your Baseline. If a human is not able to get a 70% prediction accuracy on the task, you can always think of automating a process if your models reach a similar level.
Learning: Try to be aware of the results you are going to get before you create your models. Setting some out of the world expectations is only going to disappoint you and your client.
2. Continuous Integration is the Way Forward

You have created your model now. It performs better than the baseline/your current model on your local test dataset. Should we go forward?
We have two choices-
Go into an endless loop in improving our model further.
Test our model in production settings, get more insights about what could go wrong and then continue improving our model with continuous integration.
I am a fan of the second approach. In his awesome third course named Structuring Machine learning projects in the Coursera Deep Learning Specialization , Andrew Ng says —
“Don’t start off trying to design and build the perfect system. Instead, build and train a basic system quickly — perhaps in just a few days. Even if the basic system is far from the “best” system you can build, it is valuable to examine how the basic system functions: you will quickly find clues that show you the most promising directions in which to invest your time.”
Done is better than perfect.
Learning: If your new model is better than the current model in production or your new model is better than the baseline, it doesn’t make sense to wait to go to production.
3. Your model might break into Production
Is your model better than the Baseline? It performed better on the local test dataset, but will it really work well on the whole?
To test the validity of your assumption that your model is better than the existing model, you can set up an A/B test. Some users(Test group)see predictions from your model while some users(Control) see the predictions from the previous model.
In fact, this is the right way to deploy your model. And you might find that indeed your model is not as good as it seems.
Being wrong is not wrong really, what’s wrong is to not anticipate that we could be wrong.
It is hard to point out the real reason behind why your model performs poorly in production settings, but some causes could be:
You might see the data coming in real-time to be significantly different from the training data.
Or you have not done the preprocessing pipeline correctly.
Or you do not measure the performance correctly.
Or maybe there is a bug in your implementation.
Learning: Don’t go into production with a full scale. A/B test is always an excellent way to go forward. Have something ready to fall back upon(An older model perhaps). There might always be things that might break, which you couldn’t have anticipated.
4. Your model might not even go to Production
I have created this impressive ML model, it gives 90% accuracy, but it takes around 10 seconds to fetch a prediction.
Is that acceptable? For some use-cases maybe, but really no.
In the past, there have been many Kaggle competitions whose winners ended up creating monster ensembles to take the top spots on the leaderboard. Below is a particular mindblowing example model which was used to win Otto classification challenge on Kaggle:
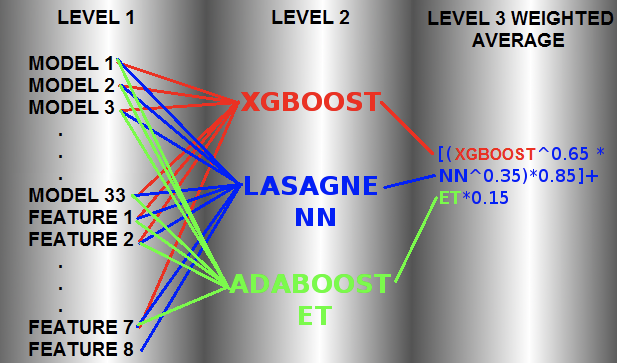
Another example is the Netflix Million dollar Recommendation Engine Challenge. The Netflix team ended up never using the wining solution due to the engineering costs involved.
So how do you make your models accurate yet easy on the machine?
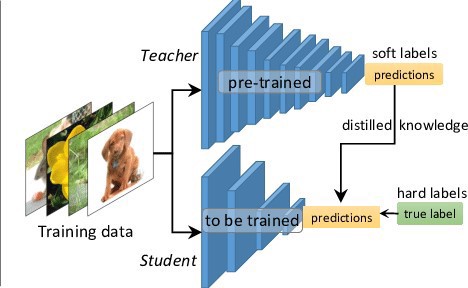
Teacher — Student Model: Source
Here comes the concept of Teacher-Student models or Knowledge distillation. In Knowledge distillation, we train a smaller student model on a bigger already trained teacher model.
Here we use the soft labels/probabilities from the teacher model and use it as the training data for the Student model.
The point is that the teacher is outputting class probabilities — “soft labels” rather than “hard labels”. For example, a fruit classifier might say “Apple 0.9, Pear 0.1” instead of “Apple 1.0, Pear 0.0” . Why bother? Because these “soft labels” are more informative than the original ones — telling the student that yes, a particular apple does very slightly resemble a pear. Student models can often come very close to teacher-level performance, even while using 1–2 orders of magnitude fewer parameters! — Source
Learning: Sometimes, we don’t have a lot of compute available at prediction time, and so we want to have a lighter model. We can try to build simpler models or try using knowledge distillation for such use cases.
5. Maintainance and Feedback Loop
The world is not constant and so are your model weights
The world around us is rapidly changing, and what might be applicable two months back might not be relevant now. In a way, the models we build are reflections of the world, and if the world is changing our models should be able to reflect this change.
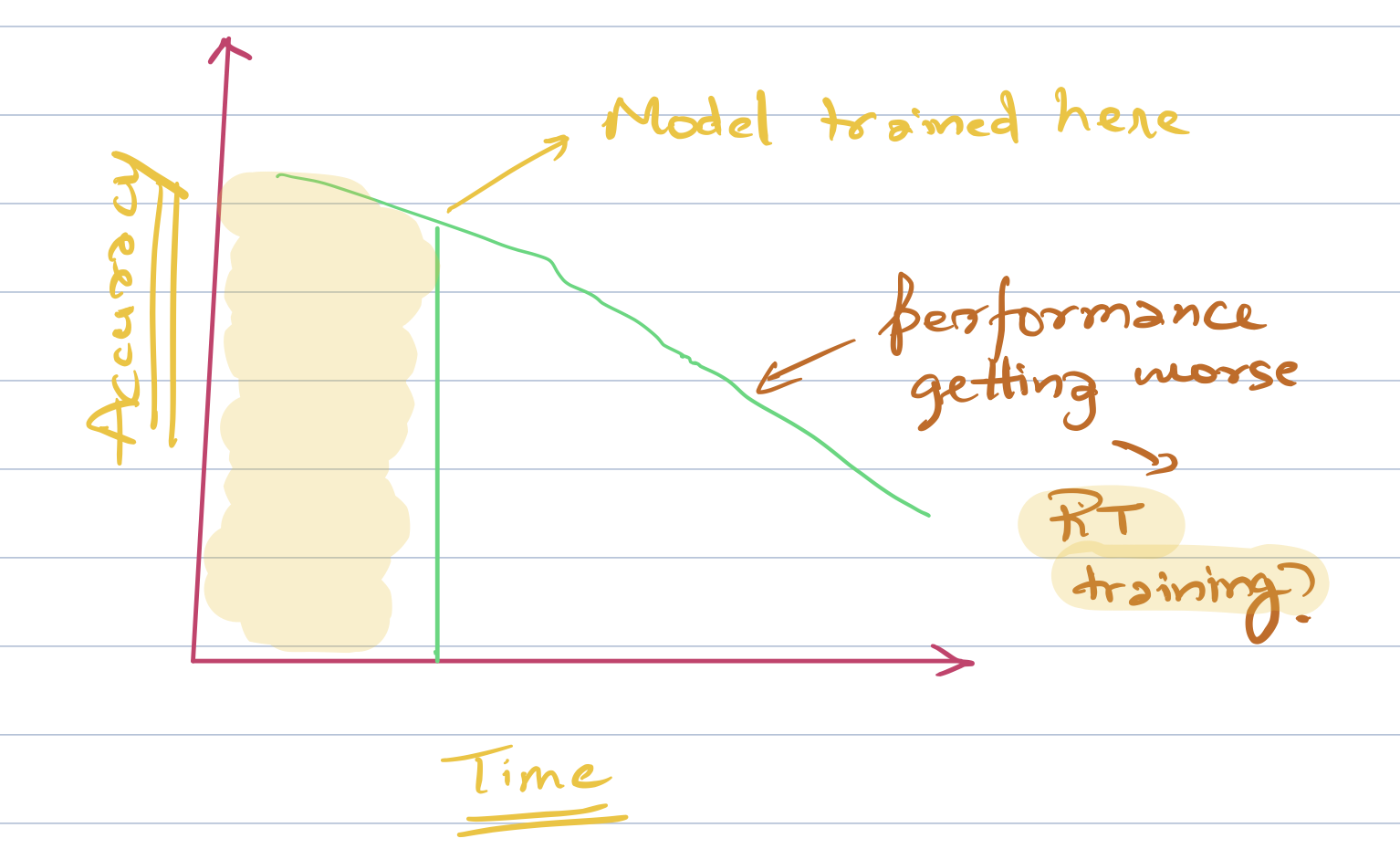
Model performance deteriorates typically with time.
For this reason, we must think of ways to upgrade our models as part of the maintenance cycle at the onset itself.
The frequency of this cycle depends entirely on the business problem that you are trying to solve. In an Ad prediction system where the users tend to be fickle and buying patterns emerge continuously, the frequency needs to be pretty high. While in a review sentiment analysis system, the frequency need not be that high as language doesn’t change its structure quite so much.
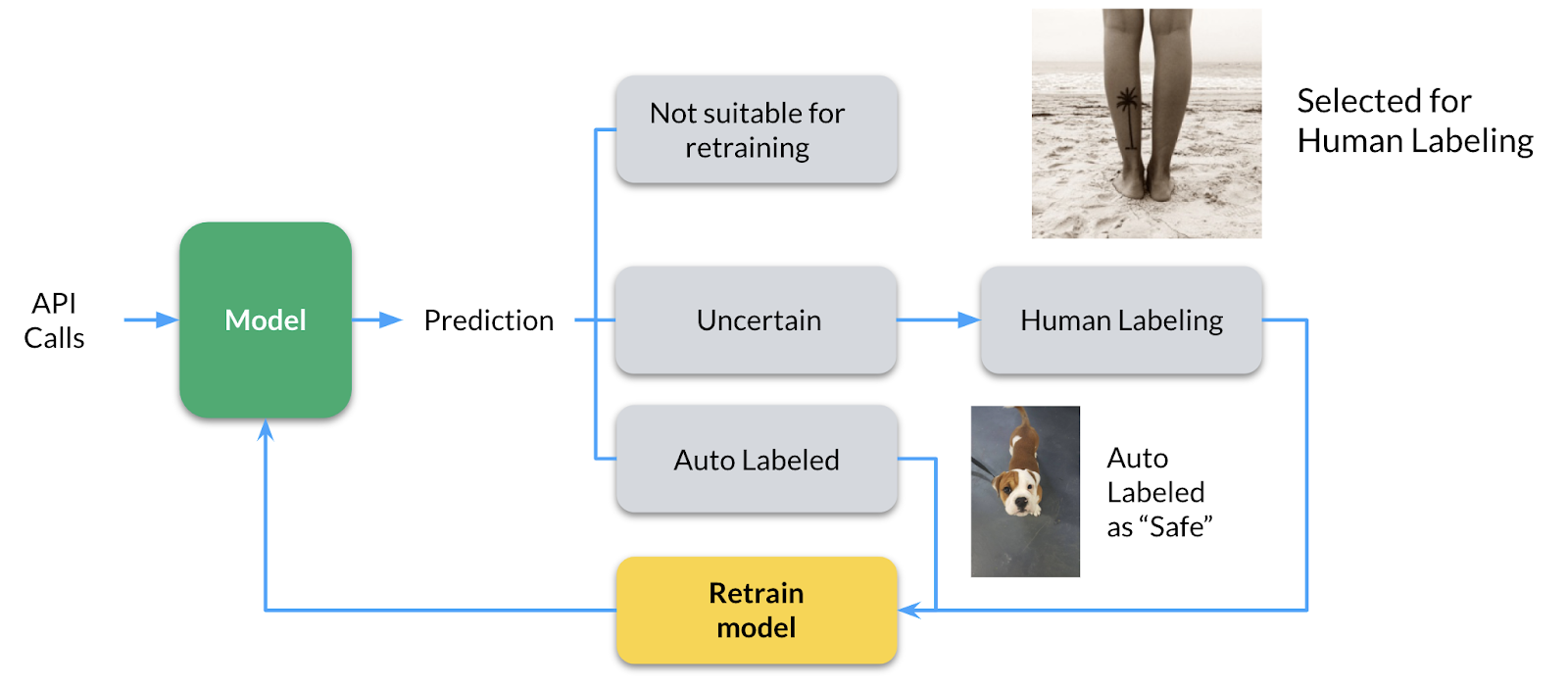 Feedback Loop:
Source
Feedback Loop:
Source
I would also like to acknowledge the importance of the feedback loop in a machine learning system. Let’s say that you predicted that a particular image is a dog with low probability in a dog vs cat classifier. Can we learn something from these low confidence examples? You can send it to manual review to check if it could be used to retrain the model or not. In this way, we train our classifier on instances it is unsure about.
Learning: When thinking of production, come up with a plan to maintain and improve the model using feedback as well.
Conclusion
These are some of the things I find important before thinking of putting a model into production.
While this is not an exhaustive list of things that you need to think about and things that could go wrong, it might undoubtedly act as food for thought for the next time you create your machine learning system.
If you want to learn more about how to structure a Machine Learning project and the best practices, I would like to call out his excellent third course named Structuring Machine learning projects in the Coursera Deep Learning Specialization . Do check it out.
Thanks for the read. I am going to be writing more beginner-friendly posts in the future too. Follow me up at Medium or Subscribe to my blog
About Me

I’m a Machine Learning Engineer based in London, where I am currently working with Roku .
Know More