


Crack ML System Design Interviews Like a Pro - Part II
Netflix Real-World Case Study


In the first part of this blog post, I talked about the framework for handling ML Interviews. Now let’s dive into what many consider the most valuable part of ML interview prep – real-world case studies. I’ve carefully selected this example because it represents the problems you’re likely to encounter both in interviews and on the job. This case study follows our design framework from the last post, but with specific implementation details that make these systems work in production.
So without delay, picture this scenario: You’re in an interview at Netflix, and they ask you to design their content recommendation system. This isn’t just a theoretical exercise – Netflix estimates that their recommendation system saves them $1B+ yearly in customer retention. Let’s break this down step by step, using our framework from the last post.
Requirements Gathering
First, let’s nail down those requirements. Remember – don’t jump into solutions yet! Here are may be some of the key questions you should/could ask so that the interviewer knows that you are thinking in the right direction and if not it could help them guide you in the right direction:
A. Scope Clarification (high-level goals and boundaries for what the system should achieve):
Increase user engagement and retention: The system should keep users engaged with the platform by providing relevant and interesting content recommendations. This includes analyzing viewing patterns, understanding user preferences, and maintaining a balance between familiar and new content types.
Reduce time-to-play (how quickly users find something to watch): Users should quickly find the content they want to watch. Every second a user spends browsing without playing content is a potential risk for user dissatisfaction. The system should minimize the "decision paralysis" that comes with too many choices.
Increase content diversity: Help users discover new content whenever they visit the page. The system needs to optimize for both exploration and exploitation in content recommendations.
Optimize content ROI: Netflix invests heavily in original content and licensed materials. The recommendation system should optimize the return on these investments by ensuring content reaches its ideal audience.
B. Functional Requirements (WHAT the system should do):
Each user needs to get 100 recommendations each time they refresh.
Ensure different recommendations appear on each refresh while maintaining relevance
C. Non-Functional Requirements (HOW WELL the system should do it):
200M+ active users globally
Homepage recommendations must load in <100ms
Updates: Near real-time for user behavior
Content catalog updates: Daily
Availability: 99.99% uptime
Pro Tip: In the interview, write these requirements down visibly. I have seen many folks not making good use of the whiteboard they have in front of them. Don’t be that person. They will be valuable when justifying design decisions later.
Architecture Planning
Now we have an idea of the system we have to make. Let’s design our system piece by piece. Here’s where your understanding of both ML and system design comes together. First, let’s create a basic recommendation engine.

This would work but this would not work in 50 ms. Also, this will not solve the refresh case we need to solve. How can we come up with a better design? One way is to go batch processing way where we:
Generate a large pool of 500-1000 candidates for each user
Use some sampling from this pool to show 100 items each time. We can do some form of impression discounting.
Update this pool periodically (every few hours) to maintain freshness
Let’s add this to the system:
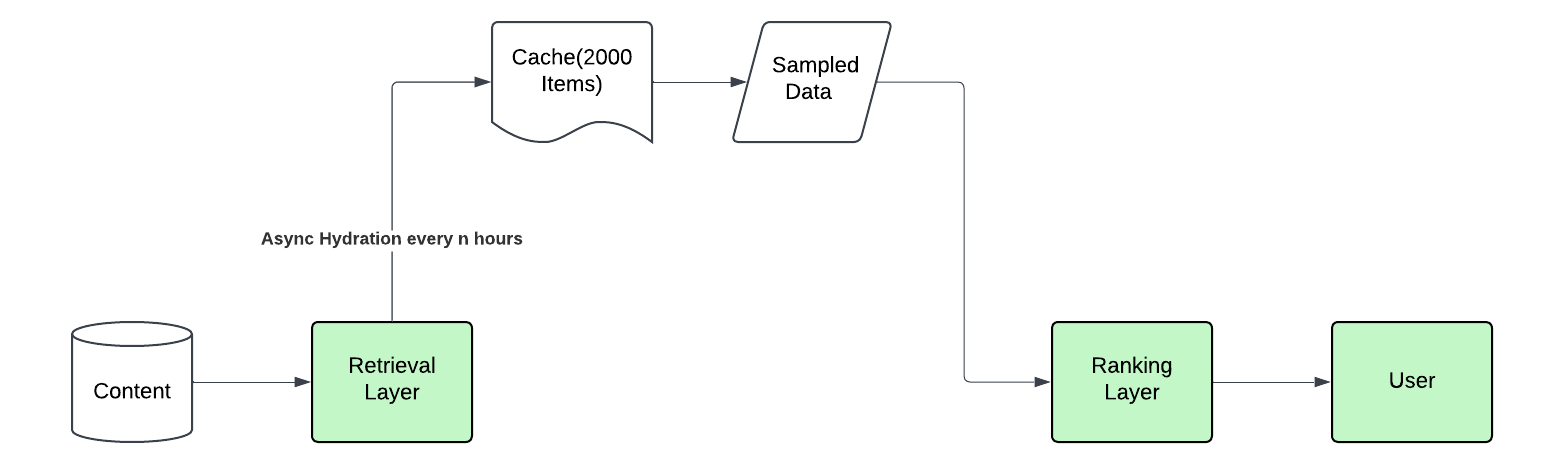
This will work for a starting architecture as it solves, two of our problems.
The latency of such a system is low as we have particularly removed the retrieval layer through a cache.
Since we are doing probabilistic sampling, we will see different recommendation lists every time.
There are some trade-offs though:
Doing sampling is not the best way as we might not show the best item to the user.
Removing retrieval with a caching layer reduces some of the performance of the system.
But this is a good start. Now we know the various pieces. In an actual interview, you would create a design that handles the requirements, and move on to the next part so that you can go through the whole system and talk through the whole design.
Evaluation and Metrics
How are you going to evaluate your success? This is a crucial part of the system design interview as it shows your product fit and product thinking. Can you understand and differentiate between stakeholder metrics and model metrics. Not everything is about getting the lowest log-loss.
A. Model Metrics:
Coming back to our system, some common offline evaluation metrics for recommendation systems that I would use would be:
NDCG/MRR
MAP@k
B. Business Metrics:
We will also need to define some online metrics based on the requirements of the business that bring in the buck:
Average Streaming Hours: Time users spend watching content
Time to Play: How quickly users start streaming after logging in
Session Diversity: Variety of content types per viewing session
Long-term Diversity: Content variety across multiple sessions
Revenue Impact: Direct correlation with subscription retention
User Satisfaction: Measured through explicit and implicit feedback
Data Pipeline Design
Data Collection:
Events:
User explicit feedback (ratings, likes)
Implicit feedback (watch time, browsing patterns)
Features:
User features: watch history, genre preferences, viewing times, user embeddings
Content features: content embeddings, popularity scores, freshness
Contextual features: time of day, device type
Cold start handling for new users/content
Data Validation/ Cleaning:
This is where real-world experience really helps. We will need to validate:
Data completeness (are we missing crucial fields?)
Data accuracy (is that 10-hour viewing session real or a bug?)
Data freshness (how recent is our user behavior data?)”
Training Infrastructure
Retrieval Model Architecture
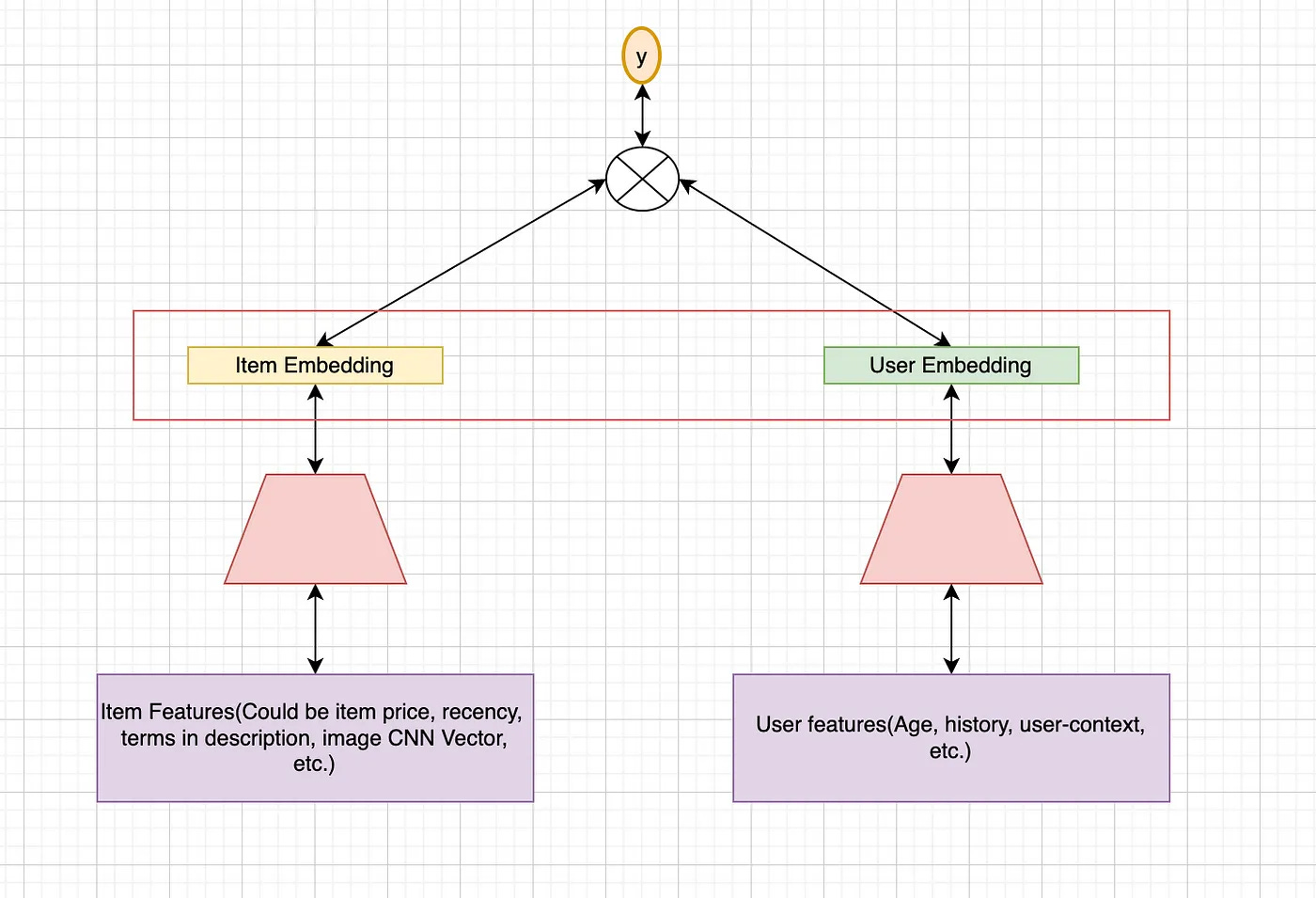
Two-tower architecture: Though we are using an async system, we can still go ahead with Two tower architecture and store our results in a cache, every n hours. If you don’t know how Two Tower Network works look into my blog here
User tower: processes user and context features
Content tower: processes item features
Final layer: Dot product for user-item similarity
Retrieval Training Strategy
Negative sampling from unwatched content
Time-based split for validation
Multiple objective optimizations (watch time, clicks, launches)
Loss: Binary cross entropy
Ranking Model Architecture
We start with the Linear Models as we need fast results.
We can try to go for deep rankers as well based on what we observe in latency at a later stage.
Multiple models each optimizing for different objectives. These models can run in parallel.
Weighted score from models. The weights can be online tuned using some Bayesian strategy. Note: The weighted online ranking is the particular strategy that Instagram uses for ranking reels. They have a Multi-task deep ranker which predicts multiple probabilities. The final score is a weighted sum of these values. The weights are tuned by an online system.
Deployment and Serving
Here I will talk about various parts of how I would serve such a system.
Candidate Pre-computation System: The foundation of our recommendation serving system lies in its batch processing pipeline, which runs every 4-6 hours to maintain recommendation freshness while balancing computational resources. We can also create an incremental update system that only recomputes recommendations for users with new activity since the last batch run, significantly reducing unnecessary computation
Caching Infrastructure: Our caching infrastructure can employ sophisticated multi-level caching to balance performance with resource utilization.
Real-time Serving Components: At its core, the impression discounting system maintains a short-term memory of user interactions using a Redis-based implementation. Our real-time ranking component consists of two main services. The feature service handles real-time computation of dynamic features, integrates current user context, and updates content popularity metrics on the fly.
Monitoring and Alerting: Our infrastructure monitoring tracks essential system metrics including CPU, memory, and disk usage, along with network latency and throughput.
Now, is this the best system? Absolutely not. There are just so many things that need to be there to build a complex system such as Netflix. But in an interview setting, this would show your interviewer that you can think through the various ideas and be able to think of the various trade-offs. Overall this should be enough to pass my interview.
PS: You might have to get into particular parts of the design based on where you are steered by the interviewer. Also, don’t feel disheartened if they don’t steer you a particular way. In some companies, it is the task of the interviewee to drive this interview and the interviewer just marks you based on the things you cover.
So that’s it from me for this iteration. Let me know how you liked this one and what I should focus on next.
Raul, Can you expand more into the kind of technologies we should use? in each part of the zone/layer of the architecture?
Both part I and II are very insightful!