
ChatGPT’s free conversational interface offers a tantalizing glimpse into the future of AI.
read more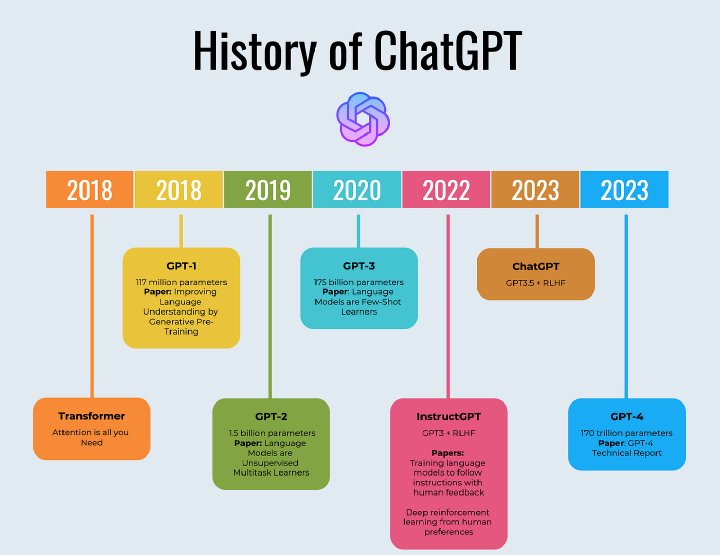
ChatGPT is what everyone is talking about nowadays. Would it take all the jobs?
read more
Or how to get better at hacking? Reading code is a hard skill to inculcate.
read more
Or How to use the export command Linux shell has become a constant part of every ML Engineer, Data Scientist and Programmer’s life.
read more
Parallelism and concurrency aren’t the same things. In some cases, concurrency is much more powerful.
read more
In my last series of posts on Transformers, I talked about how a transformer works and how to implement one yourself for a translation task.
read more
Finally, my program is running! Should I go and get a coffee?
read more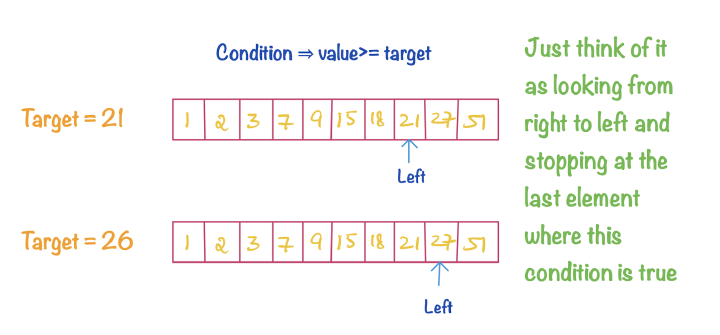
Algorithms are an integral part of data science. While most of us data scientists don’t take a proper algorithms course while studying, they are important all the same.
read more
In one of my previous posts, I talked about how to become a data Scientist using some awesome resources from Coursera .
read more
ROC curves, or receiver operating characteristic curves, are one of the most common evaluation metrics for checking a classification model’s performance.
read moreAbout Me

I’m a Machine Learning Engineer based in London, where I am currently working with Roku .
Know More